Appen is the global leader in the development
of high-quality, human annotated datasets
for machine learning and artificial intelligence.

We collect, classify, translate, review and label large volumes of image, text, speech, audio, video and other data used to build and train AI systems.
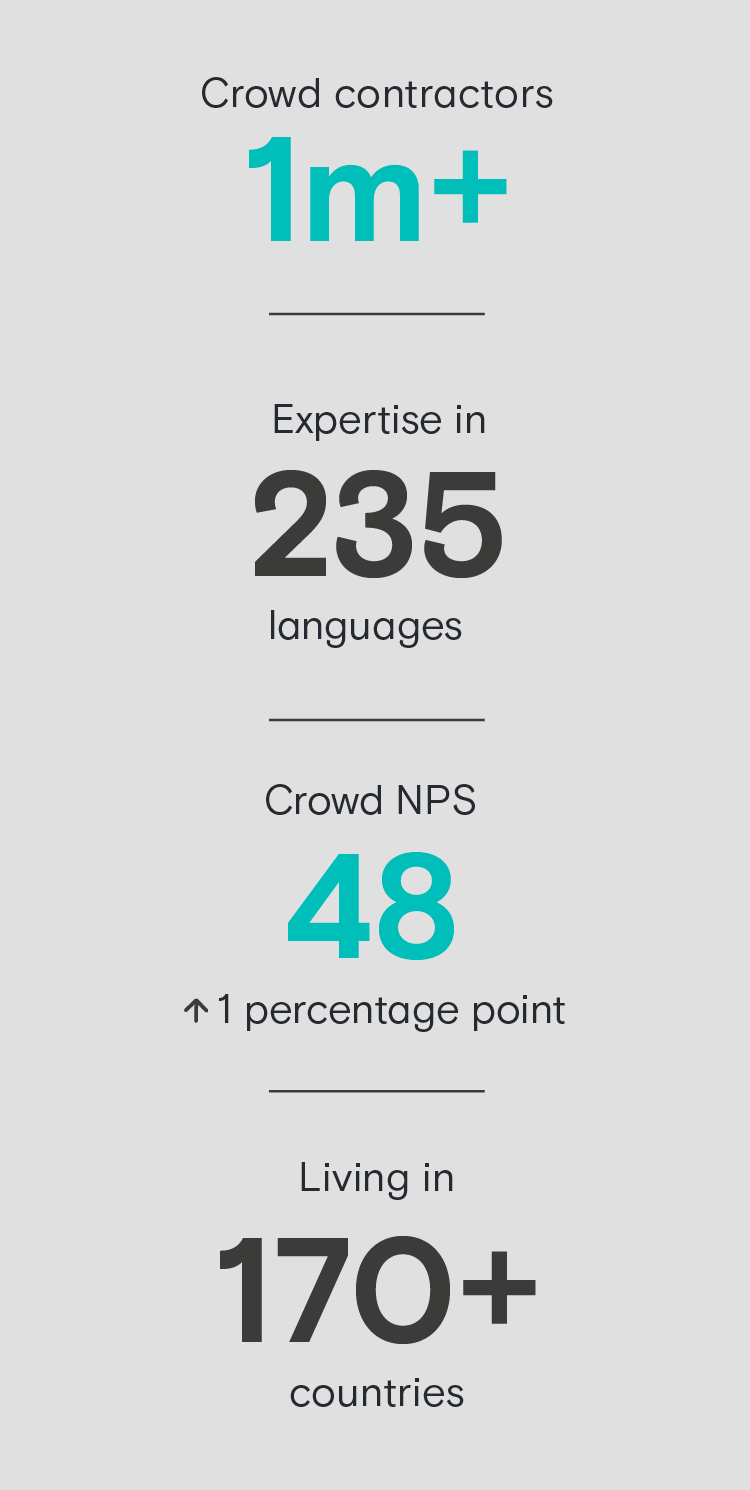
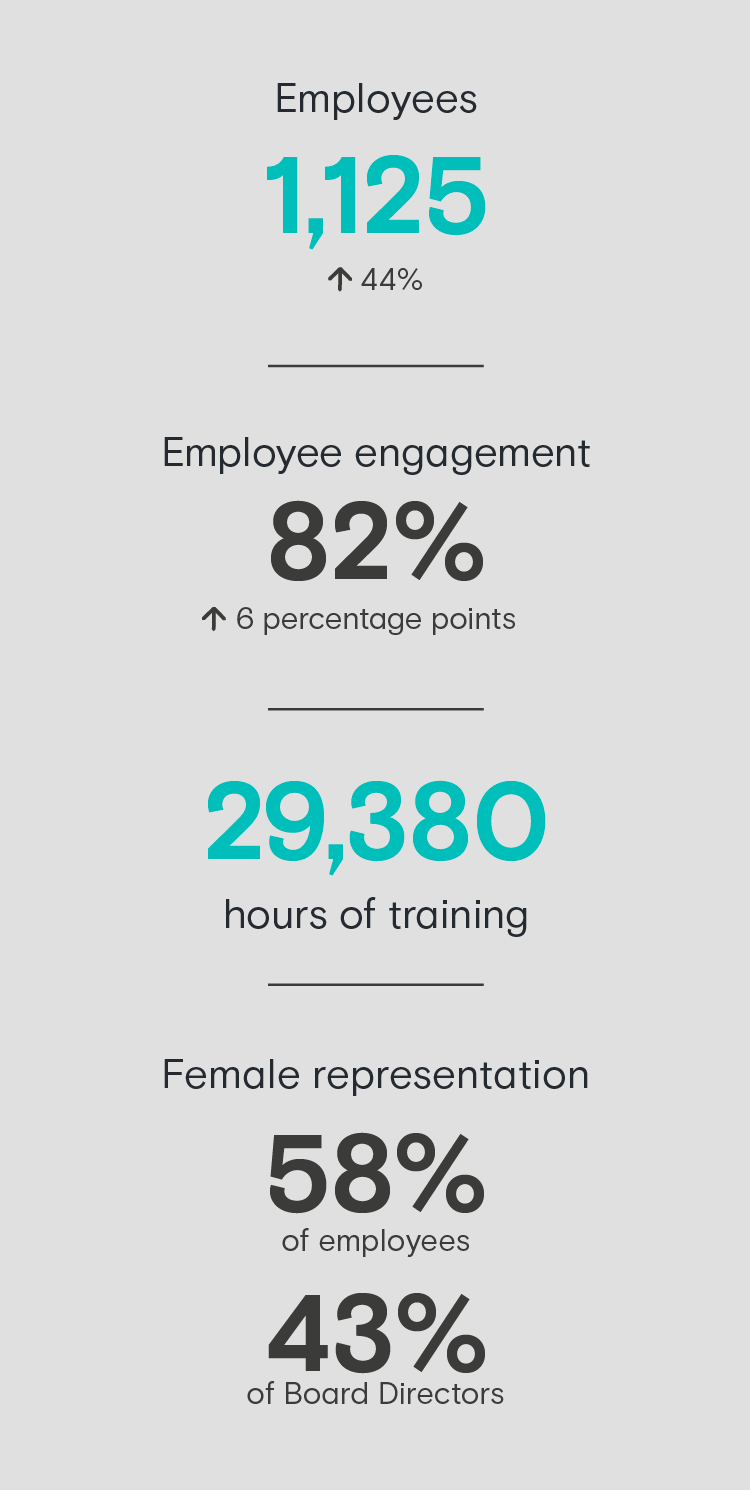
The data is annotated by our global crowd of over 1 million skilled contractors who speak 235 languages and work in over 170 countries.
We also have the industry’s most advanced AI-assisted annotation platform.

When creating AI in the real world, the data used
to train the AI is more important than the model itself.

AI models learn by observing large volumes and diverse sets of examples. These examples are called training data. For data to be understood by an AI model, it requires associated meaning. We provide this meaning by annotating the data.
AI performance is correlated with the volume, quality and diversity of data used for training. AI training data needs to be refreshed regularly.
by 2024
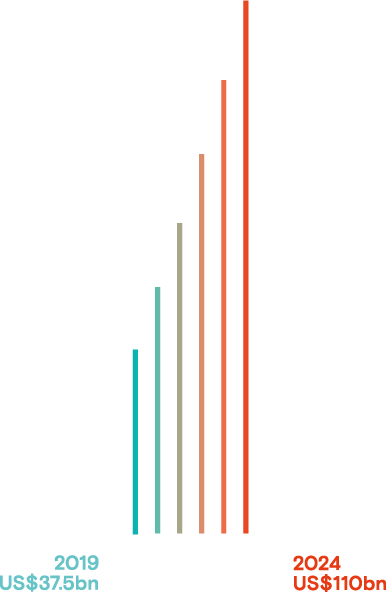

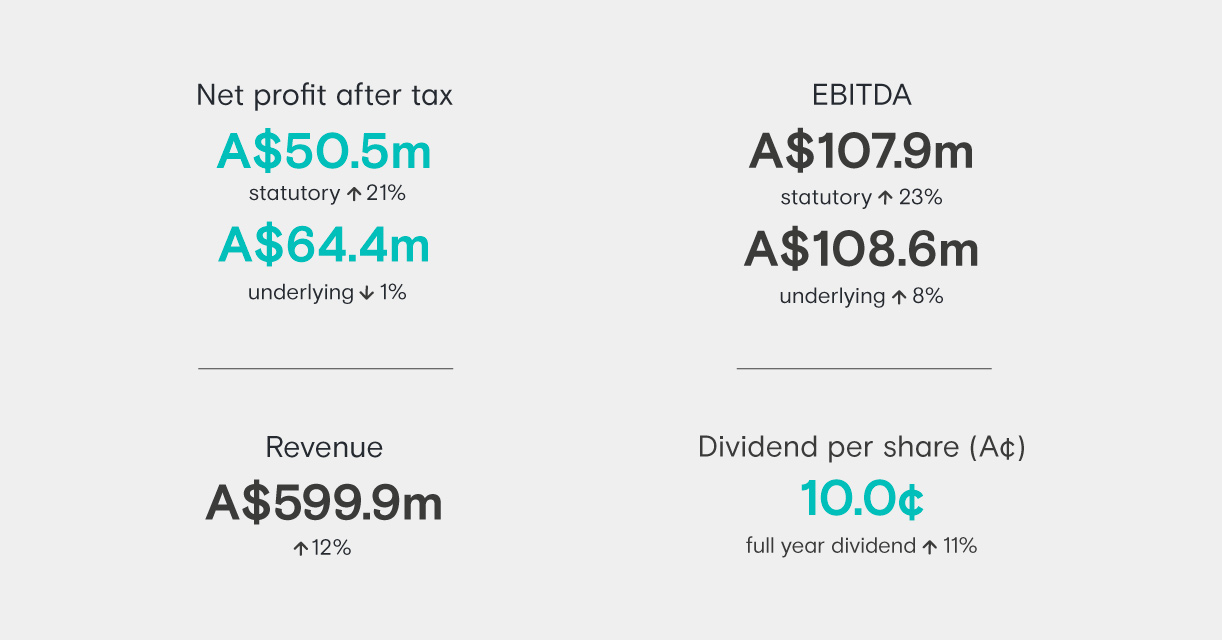
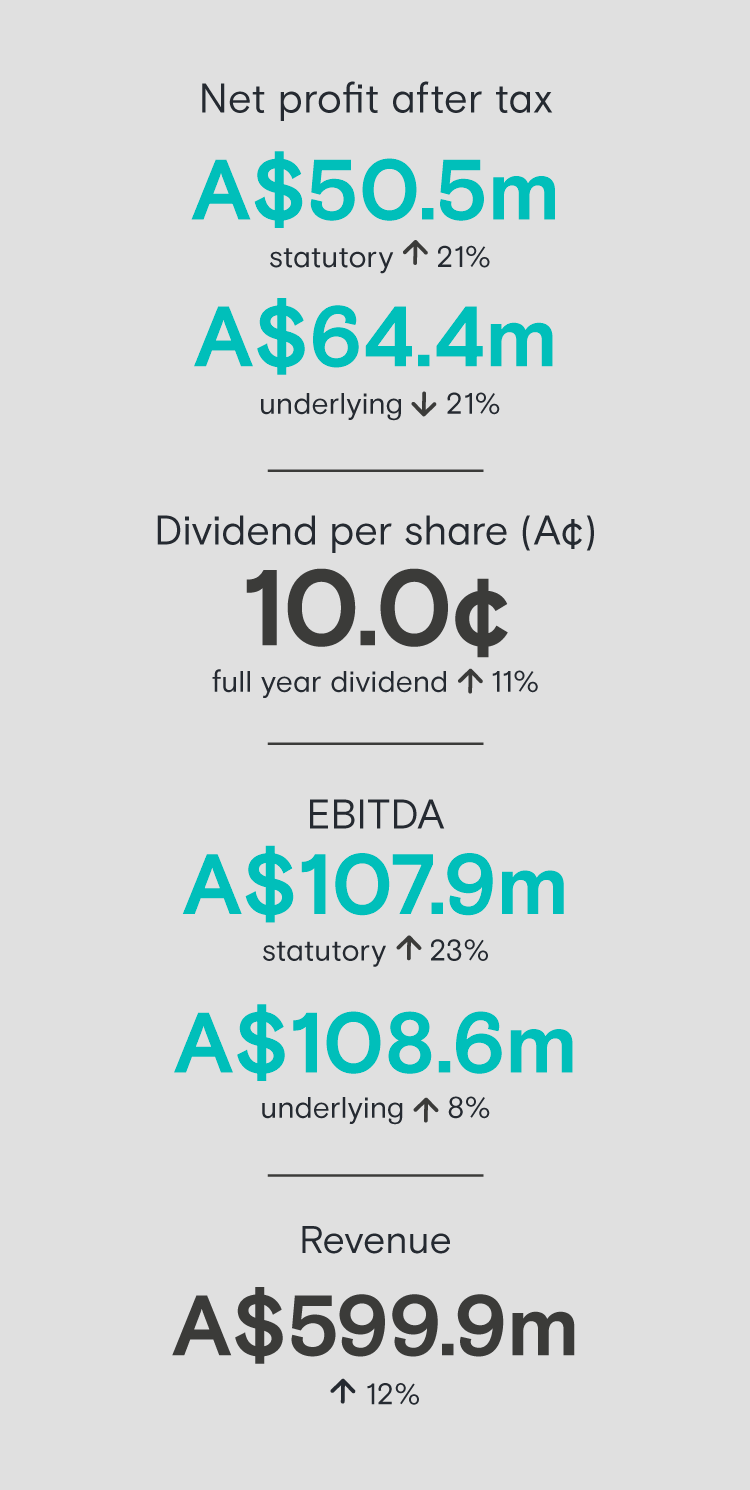
Appen continued its growth in 2020 in both revenue and earnings while navigating some headwinds arising from the global pandemic. Over the past 24 years, we have established a strong and unique role at the centre of one of the world’s most exciting industries – Artificial Intelligence and Machine Learning.
Our growth has been underpinned by the ongoing demand for high-quality training data for AI, principally from our major customers, the world’s largest technology companies, but also from many new customers.

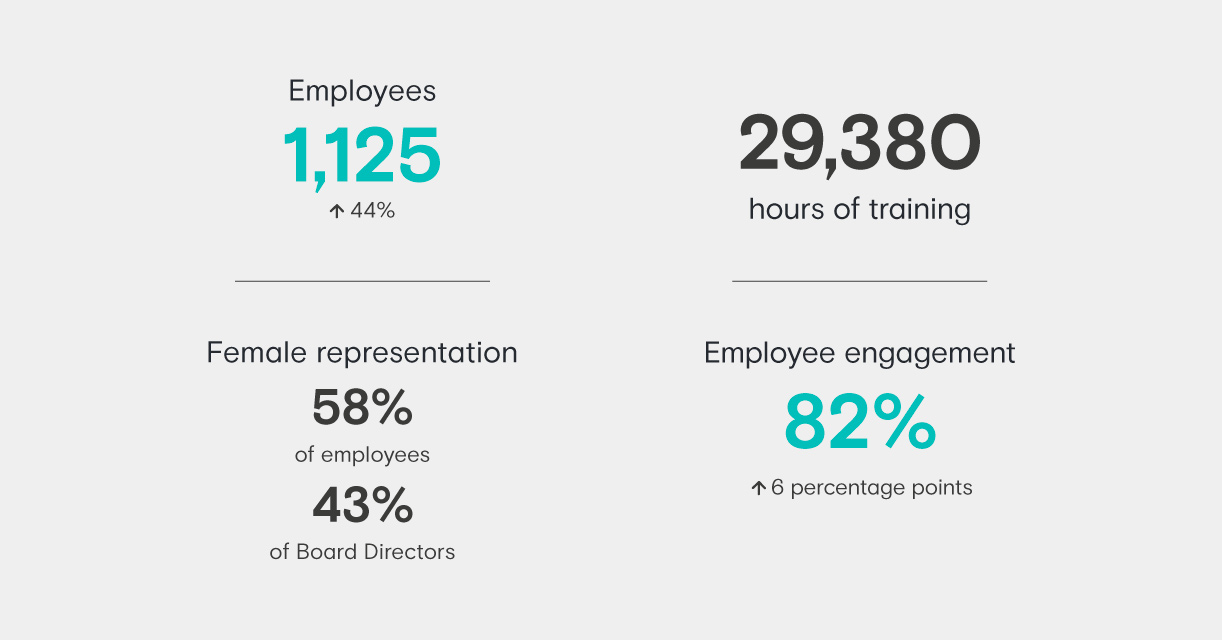
Our goals are to delight customers, have happy crowd contractors, make Appen a great place to work, be a responsible citizen and deliver strong performance for shareholders.